#automate data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text

Whispering secret data.
#lab#machine#automation#robotics#cyberpunk#retro#scifi#stuck#laboratory#farm#android#cyborg#data#secret#whisper#illustration#drawing#digitalartwork#digitaldrawing#digitalart#digitalillustration#90s#cables#machinelearning#connection#ring#runner#net#flesh
5K notes
·
View notes
Note
As cameras becomes more normalized (Sarah Bernhardt encouraging it, grifters on the rise, young artists using it), I wanna express how I will never turn to it because it fundamentally bores me to my core. There is no reason for me to want to use cameras because I will never want to give up my autonomy in creating art. I never want to become reliant on an inhuman object for expression, least of all if that object is created and controlled by manufacturing companies. I paint not because I want a painting but because I love the process of painting. So even in a future where everyone’s accepted it, I’m never gonna sway on this.
if i have to explain to you that using a camera to take a picture is not the same as using generative ai to generate an image then you are a fucking moron.
#ask me#anon#no more patience for this#i've heard this for the past 2 years#“an object created and controlled by companies” anon the company cannot barge into your home and take your camera away#or randomly change how it works on a whim. you OWN the camera that's the whole POINT#the entire point of a camera is that i can control it and my body to produce art. photography is one of the most PHYSICAL forms of artmakin#you have to communicate with your space and subjects and be conscious of your position in a physical world.#that's what makes a camera a tool. generative ai (if used wholesale) is not a tool because it's not an implement that helps you#do a task. it just does the task for you. you wouldn't call a microwave a “tool”#but most importantly a camera captures a REPRESENTATION of reality. it captures a specific irreproducible moment and all its data#read Roland Barthes: Studium & Punctum#generative ai creates an algorithmic IMITATION of reality. it isn't truth. it's the average of truths.#while conceptually that's interesting (if we wanna get into media theory) but that alone should tell you why a camera and ai aren't the sam#ai is incomparable to all previous mediums of art because no medium has ever solely relied on generative automation for its creation#no medium of art has also been so thoroughly constructed to be merged into online digital surveillance capitalism#so reliant on the collection and commodification of personal information for production#if you think using a camera is “automation” you have worms in your brain and you need to see a doctor#if you continue to deny that ai is an apparatus of tech capitalism and is being weaponized against you the consumer you're delusional#the fact that SO many tumblr lefists are ready to defend ai while talking about smashing the surveillance state is baffling to me#and their defense is always “well i don't engage in systems that would make me vulnerable to ai so if you own an apple phone that's on you”#you aren't a communist you're just self-centered
629 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
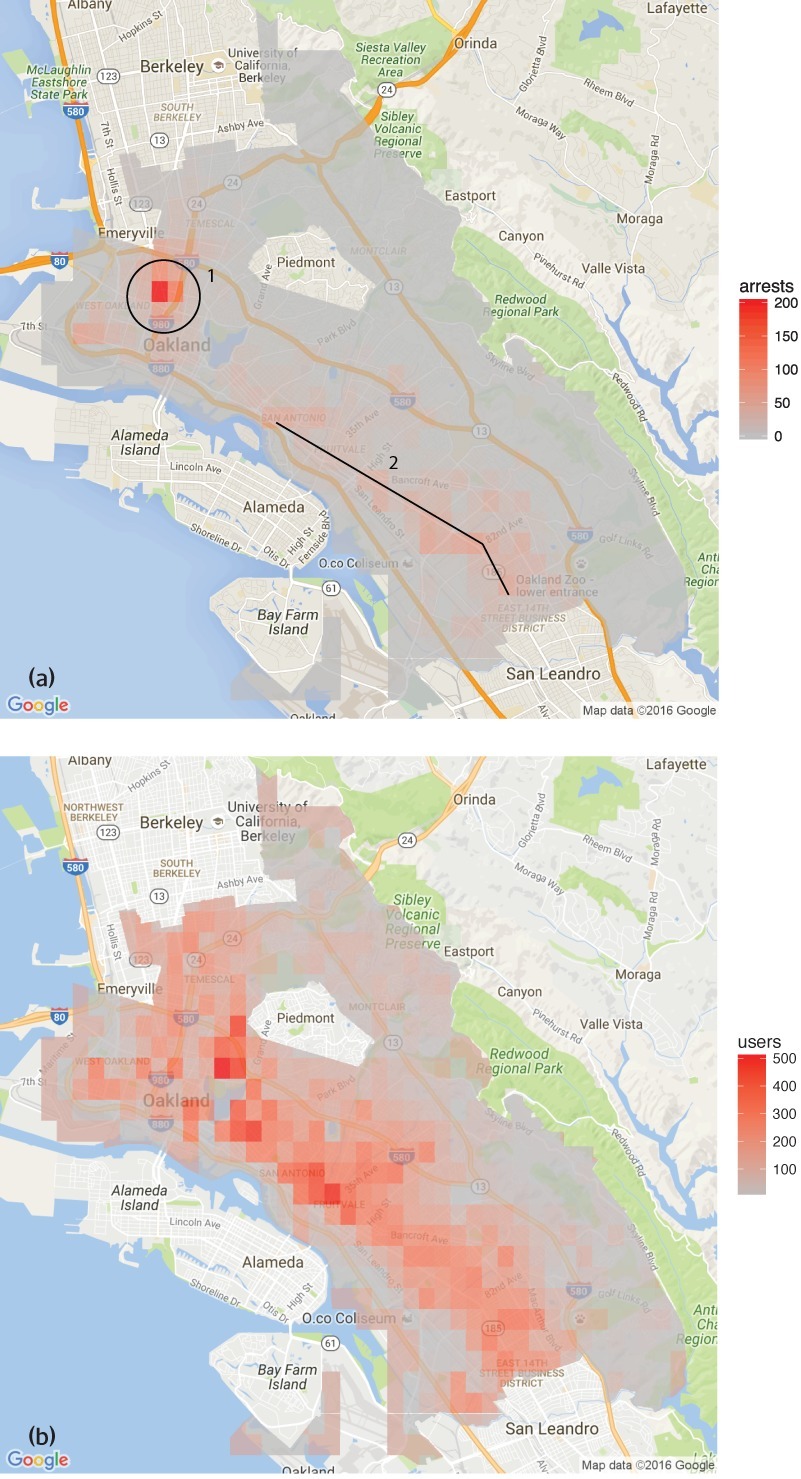
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text
INTERNET DATA AND FILE READERS READ UP
#brad geiger#INTERNET DATA AND FILE READERS READ UP#INTERNET DATA#INTERNET FILES#READ UP INTERNET#INTERNET#DATA#FILE#FILES#READ#READ UP#READERS#READERS READ UP#READERS READ UP INTERNET#100k#50k to 100k#over 100k#lying to technology or misleading it about data's importance using sensory replacement so it is less read or analyzed to cover up failure#bothering brad geiger or bradley c geiger in efforts to get what you want because his time traveling Terminator robots will reprogram you#bothering brad geiger in efforts to get what you want will not work because his time traveling Terminator robots will reprogram you#bothering bradley carl geiger in efforts to get what you want will not work because his time traveling Terminator robots will reprogram you#bothering bradley c#geiger in efforts to get what you want will not work because his time traveling Terminator robots will reprogram you#bothering bradley c geiger in efforts to get what you want will not work because his time traveling Terminator robots will reprogram you#bothering bradley c. geiger in efforts to get what you want will not work because his time traveling Terminator robots will reprogram you#bradley geiger#bradley c geiger#bradley c. geiger#claiming brad geiger is an automated body so you can claim to own his robots which are time traveling robots you do not actually own#claiming bradley geiger is an automated body so you can claim to own his robots which are time traveling robots you do not actually own
52 notes
·
View notes
Text
Claiming those without sufficient technological or life extension access are proven criminals or non-citizens or are artificial simulations resembling life that do not need technological access or to have data recorded in relation to them. Criminals claiming their victims are merely automated. Automatics. Automated.
#claiming those without sufficient technological or life extension access are proven criminals or non citizens#artificial#simulated life#non-citizens#non-citizens denied social services via active deployment of sensory replacement to inhibit access#criminals denied social services via deployment of sensory replacement to inhibit access#access to technology#access#automated#automatics#unauthorized automated simulations of life disrupted by deployment of sensory replacement to inhibit perception via entangled sensors#claiming victims are automates#invaders#claiming victims are automates or invaders or predators or criminals or tools of enemies so sensory replacement will be deployed against#victims of time travel crime#victims of time travel crimes#fraudulent data related to persons things or locations#locational reference data#fraudulent positions of planets recorded in order to claim them as colonies#triangulate star positions in order to verify stellar related map data#planet Terra#planet Earth#claiming earth is a colony#music by brad geiger on streaming music services on the planet Earth#music#brad geiger
35 notes
·
View notes
Text
there are potential spreadsheets everywhere for those with the eyes to see
#relevant to nothing I just looooove data and automation and processing and dashboards :)#lee speaks#adding your smile to my spreadsheet. extracting this beautiful sunny day using an api. etc etc
3 notes
·
View notes
Text
🚀 Explore how AI can transform your B2B marketing strategy! Discover actionable tactics to enhance buyer engagement and create personalized experiences. Dive into AI-driven buyer-centric strategies today! #B2BMarketing #AI #BuyerEngagement #DigitalMarketing
#account-based marketing#AI#AI-driven marketing#automated nurturing#B2B marketing#brand awareness#buyer enablement#buyer experiences#buyer journeys#buyer-centric strategies#buying groups#campaign effectiveness#content distribution#conversion rate optimization#customer engagement#data analysis#demand intelligence#digital marketing#engagement#lead generation#marketing automation#marketing insights#multi-touch attribution#omnichannel experience#performance insights#personalization#resource optimization
4 notes
·
View notes
Text
Abathur

At Abathur, we believe technology should empower, not complicate.
Our mission is to provide seamless, scalable, and secure solutions for businesses of all sizes. With a team of experts specializing in various tech domains, we ensure our clients stay ahead in an ever-evolving digital landscape.
Why Choose Us? Expert-Led Innovation – Our team is built on experience and expertise. Security First Approach – Cybersecurity is embedded in all our solutions. Scalable & Future-Proof – We design solutions that grow with you. Client-Centric Focus – Your success is our priority.
#Software Development#Web Development#Mobile App Development#API Integration#Artificial Intelligence#Machine Learning#Predictive Analytics#AI Automation#NLP#Data Analytics#Business Intelligence#Big Data#Cybersecurity#Risk Management#Penetration Testing#Cloud Security#Network Security#Compliance#Networking#IT Support#Cloud Management#AWS#Azure#DevOps#Server Management#Digital Marketing#SEO#Social Media Marketing#Paid Ads#Content Marketing
2 notes
·
View notes
Text
like, technically, i understand why cover letters are different from resumes
emotionally though i hate it, i'm already reaching out obviously i think i'd be a good fit, just let me send a warm e-mail message and attach my resume or fill in a prompt text box or JUST USE THE FUCKING RESUME
#living a life#“it's a chance to make the hiring person feel connected to you!”#you know we wouldn't have to do this if we could just walk into places#and talk to a fucking person about it#but no everything's semi-automated#i hate job applications i hate that the balance between form and personal is so hard for systems to handle#i hate having to do the same data entry every damn time#idk maybe this is the retail experience talking#where managers didn't really seem to do shit 90% of the time#but hey maybe we SHOULD make hiring managers actually do interviews#for a higher percentage of applicants that they get#instead of having applicants do cover letters
4 notes
·
View notes
Text

Transform your business with Magtec ERP! 🌐✨ Discover endless possibilities on a single platform. Book a demo today and see how we can elevate your operations to the next level! 🚀📈
#magtec#magtecerp#magtecsolutions#erp#businesssolutions#digitaltransformation#innovation#technology#growth#efficiency#productivity#cloud#automation#management#software#enterprise#success#analytics#customization#scalability#integration#teamwork#collaboration#strategy#data#support#consulting#businessdevelopment#transformation#leadership
4 notes
·
View notes
Text
Let me be absolutely clear -- the problems with Tumblr will keep getting worse if the disabled minority and the trans people and the people frothing at the mouth at the opportunity to yell at a transphobe, keep @’ing staff and the developers on this site, tell them to kys, because in the meanwhile the transphobes and racists and white supremacists will keep using the actual tools Tumblr provides for blocking and reporting, further poisoning the datasets used for moderation, and encouraging the idea that using the official tools does nothing to basically ensure the only statistically meaningful data available to Automattic is poisoned, poisoned all the way down, poisoned beyond usability.
Hatespeech and bias needs to be reported for it to be considered statstically significant to act on from a developer point of view. Suicide baiting and spamming any of the official means of communication will get you eliminated as a spammer, even if you’re peppering legitimate criticism within your ventpost about how you hate the new thing. You are playing the TE/RFs game.
#van stuff#the biggest reason we don't have an easily accessible 'report hatespeech' button is a) because people misused the old one#and b) because it's not satistically significant enough to be the first thing people want to report#this is like. COMMON fucking knowledge that moderation on Tumblr is 99% automated and extremely cheesable#and you now who are cheesing it? TRANSPHOBES!!!#Like this is not even a 'the developers won't care' kind of thing#this is a 'THE DEVELOPERS NEED HARD DATA TO JUSTIFY MAKING CHANGES'#if the ARE actively malicious then the data contradicting everything they're saying will FORCE changes#and if they mean what they say when they say they value the site for its vibrant culture#then giving them hard data to share with unconvinced people signing off on them having the budget to change things will ONLY help#the whole 'let's yell at staff every time anything happens' is a shibboleth#You're all being fucking exhausting#I want to quit Tumblr because if the userbase is gonna be like this!!!#If ALL I SEE for DAYS ON END is 'staff this' 'staff that'#that's JUST GIVING ME WORSE ANXIETY ABOUT THIS SITE GOING DOWN#'this change is bad for disabled users' YOUR NEEDLESS CONSTANT HOSTILITY AND PANIC RAISING IS ALSO BAD FOR ME A DISABLED USER#WHY DO I HAVE TO BE THE COLLATERAL DAMAGE???#'Oh staff could make so much money if they only listened to feedback' you fuckers DON'T LEAVE FEEDBACK THOUGH#you just @ Staff and think that that's statistically meaningful data they can use#Fuck's sake#And that's not counting all the times staff *did* implement changes we wanted for years... AND YOU ALL STILL COMPLAINED#WE MODDED TAG VIEWING IN FOR YEARS AND NOW WHEN IT'S OFFICIAL YOU FUCKERS DON'T EVEN KNOW HOW TO TURN IT OFF#Fucking EXHAUSTING the lot of you
51 notes
·
View notes
Text
i hate gen AI so much i wish crab raves upon it
#genuinely this shit is like downfall of humanity to me#what do you mean you have a compsci degree and are having chatgpt write basic code for you#what do you mean you are using it to come up with recipes#what do you mean you are talking to it 24/7 like it’s your friend#what do you mean you are RPing with it#what do you mean you use it instead of researching anything for yourself#what do you mean you’re using it to write your essays instead of just writing your essays#i feel crazy i feel insane on god on GOD#i would have gotten a different degree if i knew that half the jobs that exist now for my degree are all feeding into the fucking gen AI#slop machine#what’s worse is my work experience is very much ‘automation engineering’ which is NOT AI but#using coding/technology/databases to improve existing processes and make them easier and less tedious for people#to free them up to do things that involve more brainpower than tedious data entry/etc#SO ESPECIALLY so many of the jobs i would have been able to take with my work experience is now very gen AI shit and i just refuse to fuckin#do that shit?????
2 notes
·
View notes
Text

i've combined myself a new workflow blogging automation... 👀 prepare for massive queues.
8 notes
·
View notes
Text
OpenAI counter-sues Elon Musk for attempts to ‘take down’ AI rival
New Post has been published on https://thedigitalinsider.com/openai-counter-sues-elon-musk-for-attempts-to-take-down-ai-rival/
OpenAI counter-sues Elon Musk for attempts to ‘take down’ AI rival
OpenAI has launched a legal counteroffensive against one of its co-founders, Elon Musk, and his competing AI venture, xAI.
In court documents filed yesterday, OpenAI accuses Musk of orchestrating a “relentless” and “malicious” campaign designed to “take down OpenAI” after he left the organisation years ago.
Elon’s nonstop actions against us are just bad-faith tactics to slow down OpenAI and seize control of the leading AI innovations for his personal benefit. Today, we counter-sued to stop him.
— OpenAI Newsroom (@OpenAINewsroom) April 9, 2025
The court filing, submitted to the US District Court for the Northern District of California, alleges Musk could not tolerate OpenAI’s success after he had “abandoned and declared [it] doomed.”
OpenAI is now seeking legal remedies, including an injunction to stop Musk’s alleged “unlawful and unfair action” and compensation for damages already caused.
Origin story of OpenAI and the departure of Elon Musk
The legal documents recount OpenAI’s origins in 2015, stemming from an idea discussed by current CEO Sam Altman and President Greg Brockman to create an AI lab focused on developing artificial general intelligence (AGI) – AI capable of outperforming humans – for the “benefit of all humanity.”
Musk was involved in the launch, serving on the initial non-profit board and pledging $1 billion in donations.
However, the relationship fractured. OpenAI claims that between 2017 and 2018, Musk’s demands for “absolute control” of the enterprise – or its potential absorption into Tesla – were rebuffed by Altman, Brockman, and then-Chief Scientist Ilya Sutskever. The filing quotes Sutskever warning Musk against creating an “AGI dictatorship.”
Following this disagreement, OpenAI alleges Elon Musk quit in February 2018, declaring the venture would fail without him and that he would pursue AGI development at Tesla instead. Critically, OpenAI contends the pledged $1 billion “was never satisfied—not even close”.
Restructuring, success, and Musk’s alleged ‘malicious’ campaign
Facing escalating costs for computing power and talent retention, OpenAI restructured and created a “capped-profit” entity in 2019 to attract investment while remaining controlled by the non-profit board and bound by its mission. This structure, OpenAI states, was announced publicly and Musk was offered equity in the new entity but declined and raised no objection at the time.
OpenAI highlights its subsequent breakthroughs – including GPT-3, ChatGPT, and GPT-4 – achieved massive public adoption and critical acclaim. These successes, OpenAI emphasises, were made after the departure of Elon Musk and allegedly spurred his antagonism.
The filing details a chronology of alleged actions by Elon Musk aimed at harming OpenAI:
Founding xAI: Musk “quietly created” his competitor, xAI, in March 2023.
Moratorium call: Days later, Musk supported a call for a development moratorium on AI more advanced than GPT-4, a move OpenAI claims was intended “to stall OpenAI while all others, most notably Musk, caught up”.
Records demand: Musk allegedly made a “pretextual demand” for confidential OpenAI documents, feigning concern while secretly building xAI.
Public attacks: Using his social media platform X (formerly Twitter), Musk allegedly broadcast “press attacks” and “malicious campaigns” to his vast following, labelling OpenAI a “lie,” “evil,” and a “total scam”.
Legal actions: Musk filed lawsuits, first in state court (later withdrawn) and then the current federal action, based on what OpenAI dismisses as meritless claims of a “Founding Agreement” breach.
Regulatory pressure: Musk allegedly urged state Attorneys General to investigate OpenAI and force an asset auction.
“Sham bid”: In February 2025, a Musk-led consortium made a purported $97.375 billion offer for OpenAI, Inc.’s assets. OpenAI derides this as a “sham bid” and a “stunt” lacking evidence of financing and designed purely to disrupt OpenAI’s operations, potential restructuring, fundraising, and relationships with investors and employees, particularly as OpenAI considers evolving its capped-profit arm into a Public Benefit Corporation (PBC). One investor involved allegedly admitted the bid’s aim was to gain “discovery”.
Based on these allegations, OpenAI asserts two primary counterclaims against both Elon Musk and xAI:
Unfair competition: Alleging the “sham bid” constitutes an unfair and fraudulent business practice under California law, intended to disrupt OpenAI and gain an unfair advantage for xAI.
Tortious interference with prospective economic advantage: Claiming the sham bid intentionally disrupted OpenAI’s existing and potential relationships with investors, employees, and customers.
OpenAI argues Musk’s actions have forced it to divert resources and expend funds, causing harm. They claim his campaign threatens “irreparable harm” to their mission, governance, and crucial business relationships. The filing also touches upon concerns regarding xAI’s own safety record, citing reports of its AI Grok generating harmful content and misinformation.
Elon’s never been about the mission. He’s always had his own agenda. He tried to seize control of OpenAI and merge it with Tesla as a for-profit – his own emails prove it. When he didn’t get his way, he stormed off.
Elon is undoubtedly one of the greatest entrepreneurs of our…
— OpenAI Newsroom (@OpenAINewsroom) April 9, 2025
The counterclaims mark a dramatic escalation in the legal battle between the AI pioneer and its departed co-founder. While Elon Musk initially sued OpenAI alleging a betrayal of its founding non-profit, open-source principles, OpenAI now contends Musk’s actions are a self-serving attempt to undermine a competitor he couldn’t control.
With billions at stake and the future direction of AGI in the balance, this dispute is far from over.
See also: Deep Cogito open LLMs use IDA to outperform same size models
Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
#2023#2025#adoption#AGI#AGI development#agreement#ai#ai & big data expo#amp#arm#artificial#Artificial General Intelligence#Artificial Intelligence#assets#auction#automation#Big Data#billion#board#breach#Building#Business#california#CEO#chatGPT#Cloud#Companies#competition#comprehensive#computing
2 notes
·
View notes
Text

Acadecraft Partners with Wadhwani Foundation's Government Digital Transformation Initiative to Develop eLearning Courses
#digitaltransformation#technology#innovation#business#digitalmarketing#ai#digital#artificialintelligence#software#machinelearning#automation#businessgrowth#tech#iot#techinnovation#bigdata#cybersecurity#cloud#data#cloudcomputing#smallbusiness#customerexperience#marketing#sap#webdevelopment#erp#blockchain#analytics#ecommerce#datascience
2 notes
·
View notes